Federated Learning
When I went to NeurIPS 2019 in Vancouver, I wasn't entirely sure what to expect. I wasn't actively involved in the ML research community but orbited that part of the world for a while. After it was all said and done, the most exciting and memorable sessions were on the work being done in Federated Learning. This post is a (relatively) general overview of the area from my notes there.
Machine learning applications have seen a dramatic rise in software systems in the last decade, from straightforward recommendation systems (Netflix, etc.) to predicting what you're going to type in an email (Gmail) or keyboard (Gboard). As companies quickly embraced ML, there has been increasing tension from privacy experts about what happens with user generated data that's being used to train these models.
The general model most people have in their minds about this process goes something like this:
- User devices send data to a central system owned by some company.
- This central system takes that data and uses it to train a model.
- That model is used to, in one way or another, improve the user's experience when engaging with the application.
The key issue here is that user generated data is being sent from their devices (phones, etc.) to a central location for model training. This in turn leads to a few problems:
- Gaps in regulation (depending on your domain) make it unclear what can and cannot be done with your data.
- There is a monetary cost to uploading data (depending on a user's data plan) that may be a factor.
- A company that wants to train ML models on data but can't access it at a central location (maybe due to regulation, say HIPAA, or just the nature of your domain), will have a more difficult time incorporating these techniques into their product offering.
When reading discussions, this leads to a predictable false dichotomy: you must either give up your data to enjoy modern software, or forget about using these services.
What is often lost in those discussions is the recognition that user devices are not just "storage devices" for their information. They are generally powerful computing devices.
What if we could train ML models directly on a user's device and eliminate the need to transmit their data?
Instead of needing to send user data over the internet to a central location for training, Federated Learning works by training models on individual user devices. Rather than transmitting data to the place where models are trained, we just transmit model details and keep the data where it is.
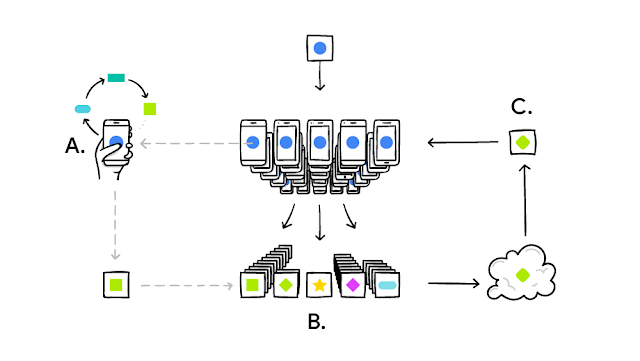
In practice, the process looks something like this:
- The central server trains a generic, shared model.
- There exists some process of deciding which clients will be involved in training the model.
- Each client downloads the current shared model.
- Each client trains the model based on local data (e.g. by running stochastic gradient descent)
- Each client then sends the central server the updates it made to the model.
- The server then aggregates the updates, e.g. by averaging them all (Federated Averaging).
- Repeat steps 3-6 until some end is reached (# of epochs or accuracy, etc.)
Broadly, there are two general federated systems at play: cross-silo, and cross-device.
You can imagine a cross silo federated system as one where you have multiple hospitals that don't want to share data with one another, but might want to share models built on top of that data. The cross device federated system is more generally seen in purely consumer facing settings, for example Google training a model on every user's device.
Though they are generally similar in that the learning process is federated, there are a few key differences between the two in practice. When training cross-silo systems, the nodes are generally more reliable, while cross-device setups face communication and reliability issues with the nodes (a user may turn off their phone for example, or the training process might use up too much battery / etc.). For a more in-depth discussion, I'd encourage you to read this review paper.
There aren't too many detailed descriptions of how this has been applied in practice, but if you're looking for one as a launching pad I'd encourage you to read check out this excellent post about how it's used by Mozilla Firefox.
This is not a silver bullet by any means. For example, it is theoretically possible to reconstruct training data based on model information, and so on, but in my mind this is a step in the right direction.
I'm certainly keeping an eye on literature and applications here. As these techniques are further developed, they will enable more ML solutions without compromising user privacy, and I for one am very excited by that future.